
Explainable AI
Motivation
In vielen Bereichen des alltäglichen Lebens unterstützen uns KI Modelle mittlerweile regelmäßig. Solche Modelle ähneln dabei einer "Black Box". NutzerInnen sehen zwar die Ein- und Ausgaben eines Modells, können den Entscheidungsweg jedoch nicht nachvollziehen. Dennoch werden die Entscheidungen solcher Modelle oftmals blind akzeptiert und bilden oftmals sogar die Basis für menschliche Handlungen. In kritischen Bereichen wie z.B. bei der Diagnose von Krankheiten oder dem autonomen Fahren birgt dieses Vertrauen Risiken. Neuste Errungenschaften im Bereich der Explainable AI bieten Methoden, welche die für die Entscheidungen von KI Modellen relevanten Teile der Eingabe ermitteln und den NutzerInnen präsentieren können [2,4,8]. Diese
Methoden bieten die Möglichkeit die Entscheidung von KI Modellen sowohl zu verstehen als auch zu hinterfragen und zu verbessern.
Aufgabenstellung
Ziel der Projektgruppe ist, eine Anwendung zu entwickeln, die Entscheidungen von KI Modellen für EndnutzerInnen nachvollziehbar macht. Die Anwendung soll die Teile der Eingabe, die für die Klassenentscheidung relevant waren, visuell hervorheben und eine textuelle Erklärung der Entscheidung in natürlicher Sprache erzeugen. Dabei erzeugt die textuelle Erklärung eine Brücke zwischen den relevanten Teilen und der Klassenentscheidung. Um eine möglichst intuitive Bedienung zu gewährleisten, soll die Anwendung als Android-App entwickelt werden. Abhängig von den benötigten Ressourcen kann die Inferenz der Modelle auf einem mobilen Endgerät oder über eine Verbindung zu einem GPU-Server berechnet werden. Die Domäne in der die Anwendung erprobt werden soll, beschränkt sich zunächst auf das Erkennen und Erklären von Objekten des alltäglichen Lebens, kann jedoch auch auf spezifischere Bereiche wie Röntgendiagnosen oder Bestimmung von Tieren erweitert werden. Dadurch entsteht eine "ExpertenApp", die Laien auf Details hinweist, die ohne Expertenwissen leicht zu übersehen sind.


Hierarchische Daten
Ausgangspunkt für die Projektgruppe ist ein Datensatz mit hierarchischen Annotationen, wie z.B. PASCAL-Panoptic-Parts [3]. In solchen Datensätzen sind nicht nur die Objekte selbst annotiert, sondern auch die einzelnen Bestandteile der Objekte. Abbildung 1 zeigt ein Beispiel eines solchen Datensatzes. Im Bild ist nicht nur das Flugzeug annotiert, sondern auch die Bauteile des Flugzeugs, wie z.B. die Flügel und Triebwerke. Mit Hilfe eines solchen hierarchischen Datensatzes entwickelt die Projektegruppe zunächst zwei Klassifikationsmodelle. Ein Objekt-Modell für die Klassifikation von Objekten im Ganzen, und ein Teile-Modell für die Klassifikation von Objektteilen. Innerhalb der Anwendung, arbeiten diese beiden Modelle letztendlich kaskadiert um die Eingaben für einen natürlichsprachlichen Textgenerator zu erzeugen.
Explainability – XAI
Die Offenlegung des Entscheidungsprozesses aktueller KI Modelle ist der zentrale Baustein des geplanten Vorhabens. Im Gegensatz zu Black Box Ansätzen, bei denen die Struktur des Modells verborgen bleibt, greifen White Box Modelle direkt in die Struktur des Modells ein und propagieren die Informationen, welche zu einer Entscheidung geführt haben, wieder zurück durch das Netz, um zu bestimmen warum ein Objekt als eine Klasse erkannt wurde. Im Bereich der White Box Modelle haben sich in den letzten Jahren unterschiedliche Ansätze hervorgetan. Lokale Erklärungen versuchen durch das Hervorheben eines entsprechenden Bildbereiches (Heatmap) die für die Modellentscheidung wichtigen Objekt(-teile) zu bestimmen [4,8]. Aktuelle Erklärungsversuche gehen noch einen Schritt weiter und versuchen nicht nur zu erläutern wo im Bild die relevante Information zu finden ist, sondern auch wie diese zur Entscheidung beigetragen hat [1]. Mit Hilfe des Objekt-Modells soll zunächst eine gewöhnliche Klassifikation auf einem aufgenommenen Bild durchgeführt werden. Anschließend nutzt die Projektgruppe aktuelle Methoden der Explainable AI um die relevanten Bereiche zu bestimmen. Dadurch berechnet die Methode zunächst eine visuelle Erklärung. Die berechnete visuelle Erklärung soll anschließend aus der Eingabe ausgeschnitten werden und mit dem Teile-Modell erneut klassifiziert werden. Mit den Ergebnissen aus diesem Arbeitsschritt soll anschließend eine natürlichsprachliche textuelle Erklärung der Klassifikationsentscheidung erzeugt werden.
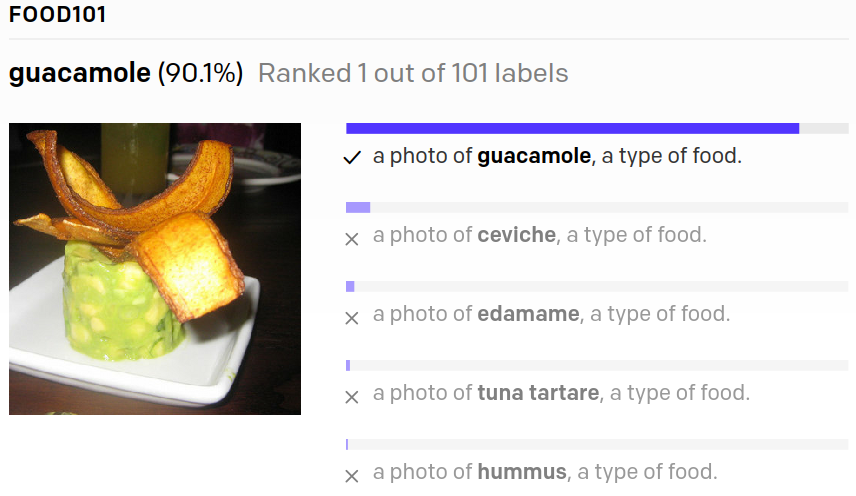
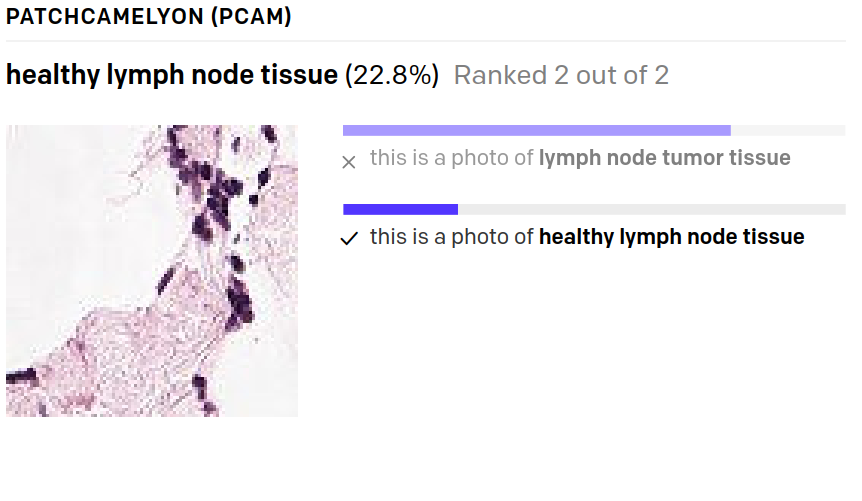
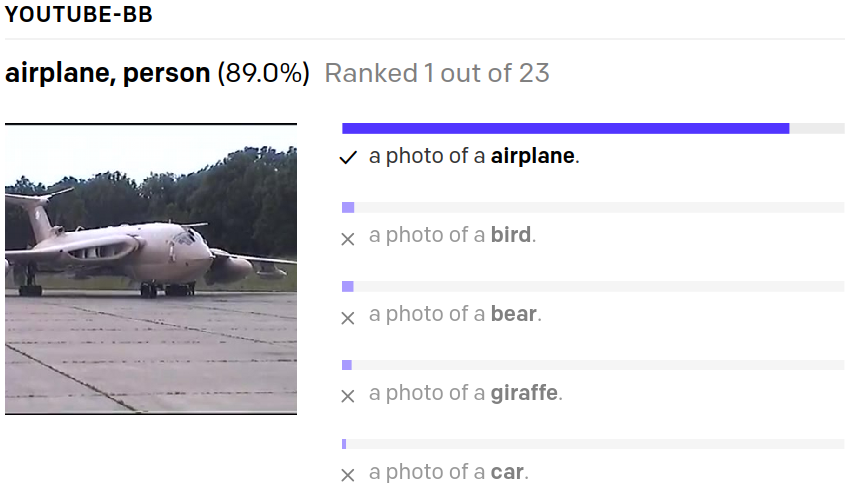
Bild-zu-Text Modelle
Da das Hervorheben einzelner Bildbereiche noch erhebliche Interpretationsspielräume beim Verständnis der Modellentscheidung für den Menschen offenlässt, soll diese Entscheidung von der zu entwickelnden Anwendung noch genauer beschrieben werden. Dabei soll eine textuelle Beschreibung in natürlicher Sprache entstehen [6], welche die visuellen Highlights ergänzt. Um dies zu ermöglichen wird auf aktuelle multi-modale Bild-zu-Text Modelle, wie z.B. CLIP [5] zurückgegriffen. Diese Modelle wurden mit milliarden, aus dem Internet gesammelten, unkuratierten Bild-Text Paaren trainiert und haben implizit ein Verständnis zwischen textueller Beschreibung und Bildinhalt gelernt, [5, 7]. Sie können genutzt werden um Bildbeschreibungen über die hierarchischen Datensätze hinaus, für eine extrem breite Palette an möglichen Objekten zu erzeugen. Falls eine bestimmte Domäne im Training dieser Modelle nicht vorkam, wie z.B. radiologische Aufnahmen, können diese auf die neue Domäne angepasst werden.
Literatur
[1] R. Achtibat, M. Dreyer, I. Eisenbraun, S. Bosse, T. Wiegand, W. Samek, and S. Lapuschkin. From ”Where”to ”What”: Towards Human-Understandable Explanations through Concept Relevance Propagation. Technical report, June 2022. arXiv:2206.03208.
[2] S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. Müller, and W. Samek. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLOS ONE, 10(7):e0130140, July 2015.
[3] D. de Geus, P. Meletis, C. Lu, X. Wen, and G. Dubbelman. Part-aware panoptic segmentation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[4] G. Montavon, S. Lapuschkin, A. Binder, W. Samek, and K.-R. Müller. Explaining nonlinear classification decisions with deep taylor decomposition. Pattern recognition, 65:211–222, 2017.
[5] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
[6] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P. J. Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020.
[7] A. Singh, R. Hu, V. Goswami, G. Couairon, W. Galuba, M. Rohrbach, and D. Kiela. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
[8] B. Zhou, A. Khosla, L. A., A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. CVPR, 2016.