
HistWeb
Motivation
In den letzten Jahrzehnten wurden Millionen von Dokumenten aus der Vergangenheit digitalisiert, um die Menschen, Ereignisse und Perspektiven einer früheren Zeit verstehen und nachzuvollziehen zu können. Die Zukunft des kulturellen Erbes im digitalen Zeitalter geht jedoch weit über diesen Digitalisierungsschritt hinaus und beschäftigt sich mit der Fragestellung, wie diese Daten exploriert und aus ihnen relevante Informationen extrahiert werden können. Hierbei sind Mustererkennung und künstliche Intelligenz essentielle Bausteine, um aus der Vielzahl an Textdokumenten, Briefen und Bildern relevante Information zu extrahieren, diese zu verbinden und zugänglich zu machen.
Im Hinblick auf historische Dokumente, haben sich Zeitungen (siehe Abbildung 1) als besonders informationsreiche Quelle herausgestellt, da diese Informationen über kulturelle, politische und soziale Ereignisse so detailliert wie kein anderes öffentliches Dokument bereitstellen. Seit ihren Anfängen im 17. Jahrhundert haben sie Milliarden von Ereignissen, Geschichten und Namen, in fast jeder Sprache, jedem Land und an jedem Tag aufgezeichnet. Eine weitere interessante Informationsquelle sind historische Postkarten (siehe Abbildung 2), da diese menschliche Interaktionen abbilden und daraus ein soziales Netzwerk der Vergangenheit erstellt werden kann.
Bitte bestätigen Sie die Aktivierung dieses Videos.
Nach der Aktivierung werden Cookies gesetzt und Daten an YouTube (Google) übermittelt.
Zur Datenschutzerklärung von Google
Bitte bestätigen Sie die Aktivierung dieses Videos.
Nach der Aktivierung werden Cookies gesetzt und Daten an YouTube (Google) übermittelt.
Zur Datenschutzerklärung von Google
Das allgemeine Ziel in dem aktuellen Forschungsbereich, ist die Entwicklung von benutzerfreundlichen Systemen, welche die Exploration der Dokumentenkollektionen ermöglichen. Ähnlich wie bei klassischen Suchmaschinen für Webseiten, muss das System hierfür in der Lage sein, die Dokumente bezüglich ihrer Relevanz zu einer natürlich sprachlichen Anfrage zu sortieren oder diese zu beantworten. Außerdem sollte es Personen, Orte und Themen eindeutig in Textdokumenten erkennen und zuordnen können.
Aufgabenstellung
Im Rahmen der Projektgruppe soll eine Webseite zur semantischen Analyse und Exploration von historischen Dokumentenkollektionen entwickelt werden. Hierzu kann auf eine Vielzahl von Arbeiten aus aktuellen Forschungsbereichen wie Natural Language Processing (NLP) und Information Retrieval (IR) zurückgegriffen werden. Insbesondere Methoden aus dem Question Answering [4], der Named Entity Recognition und Linking [3] sowie aus dem Bereich Topic Modeling [7] sind von besonderer Relevanz. Verschiedene Datensätze stehen bei der Entwicklung des Prototypen zur Verfügung. Während die ersten Entwicklungsschritte auf öffentlichen Datensätzen, wie beispielsweise einem Zeitungsdatensatz [3], erfolgen werden, soll anschließend die Möglichkeit untersucht werden, ob sich die entwickelten Methoden auf den am Lehrstuhl vorliegenden Postkartendatensatz anwenden lassen. Dieser Datensatz bietet eine Vielzahl an komplexen Problemstellungen und Charakteristika, welche über die in der Forschung verfügbaren Benchmarks hinausgehen. Das System soll abschließend im Rahmen einer zu entwickelnden Webseite präsentiert werden, welche die Exploration der Kollektionen ermöglicht und die extrahierten Informationen geeignet visualisiert.
Information Retrieval
Ein zentraler Baustein für die Exploration von Dokumentenkollektionen ist die Entwicklung eines Information Retrieval Systems. Diese soll die Dokumente bzgl. derer Relevanz zur Anfrage sortieren und dem/der Benutzer:in zurückgeben. Hierbei hat sich die Schlüsselwortsuche als intuitives Werkzeug herausgestellt. Es hat sich jedoch gerade in dem Kontext von Internetsuchmaschinen gezeigt, dass die Suche nach Schlüsselwörtern zunehmend in den Hintergrund gerät und die Beantwortung von natürlich sprachlichen Anfragen immer wichtiger wird. Daher wollen wir diesen Trend auch in dem Prototypen berücksichtigen und ein Question Answering Modell auf historischen Dokumentenkollektionen realisieren. Hierzu soll sich die Projektgruppe zunächst mit dem Thema Question Answering auf Dokumenten vertraut machen [4] und die Modelle auf den Kontext der historischen Dokumentenkollektionen übertragen. Hierzu stehen der Projektgruppe mehrere interessante Datensätze [5,6,8], Competitions [9] und Ansätze [9] zur Verfügung.
Semantische Analyse und Extraktion
Neben dem Information Retrieval soll die Projektgruppe außerdem einige Methoden zur Analyse und Informationsextraktion auf den Kollektionen implementieren und evaluieren. Hierbei stehen besonders sogenannte Named Entities (NEs) im Vordergrund, da diese häufig bei Suchanfragen an digitale Bibliotheksportale enthalten sind. Bei den NEs handelt es sich um Objekte aus der realen Welt, wie z.B. Personen, Orte und Organisationen. Da ein Wort häufig mehrere Bedeutungen haben kann, wie z.B. das Wort Washington für die Stadt und die Person (George Washington), müssen diese Entitäten in einem weiteren Schritt disambiguiert werden. Dieser Prozess wird auch als Named Entity Linking bezeichnet und bildet die NEs auf Einträge in einer Wissensdatenbank (z.B. Wikipedia) ab (siehe Abbildung 3). Für die Entwicklung und die Evaluation der Neuronalen Modelle stehen bereits annotierte Daten zur Verfügung [3].
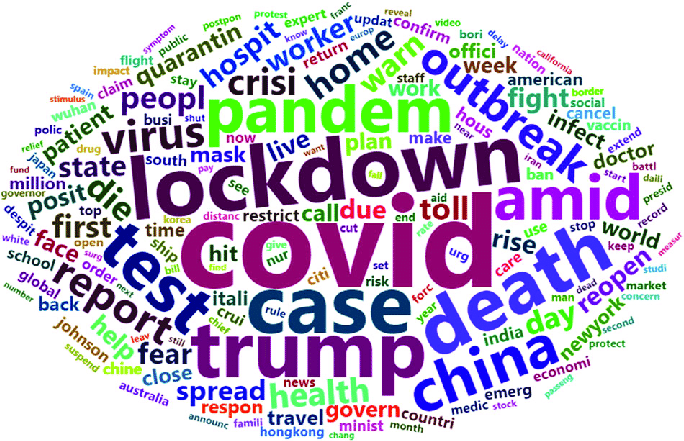
Ein weitere Aufgabenstellung könnte die Ermittlung und Visualisierung von interessanten Themen über einen bestimmten Zeitraum sein. Hierfür könnten die Zeitungsarchive genutzt werden, um für jedes Jahr eine sogenannte Topic Cloud [7] zu erstellen. In dieser Visualisierung können die User dann sehen, welche Themen in welchem Jahr besonders relevant waren und weitere Informationen zu diesen erhalten. In Abbildung 4 ist eine Topic Cloud beispielhaft für das Jahr 2019 visualisiert.
Postkarten
Während die Entwicklung neuer Methoden auf in der Forschung etablierten Benchmark Datensätzen evaluiert wird, stellt sich deren Transfer auf ''reale'' Problemstellungen häufig als schwierig heraus. Im Bereich der semantischen Analyse werden häufig gedruckte Texte betrachtet deren Erkennung zumindest teilweise möglich ist. Dies ist jedoch bei vielen historischen Kollektionen nicht der Fall. Ein solches Beispiel stellt der am Lehrstuhl verfügbare und bereits in Vorarbeiten untersuchte Feldpostkarten Datensatz dar (siehe Abbildung 2). Dieser enthält eine Vielzahl an Informationen, welche über den Textinhalt hinaus gehen. Postkarten als Kommunikationsmedium ähneln heutigen Kurznachrichten und spiegeln somit menschliche Interaktion wieder. Um diese abbilden zu können, sollen zunächst einfache Szenarien der Informationsextraktion definiert und Methoden für diese entwickelt werden. Hierbei kann es sich beispielsweise um die Extraktion von Empfängern, Poststempeln oder um die Datierung der Karten handeln. Anschließend soll in Kooperation mit den anderen Teilgruppen evaluiert werden, ob sich die entwickelten Methoden des Question Answerings, der semantischen Analyse oder des Topic Modelings auf den Datensatz anwenden lassen.



Literatur
[1] M.-F. Aslam, T. Awan, A. Kashif, and M. Parveen. Sentiments and emotions evoked by news headlines of coronavirus disease (covid-19) outbreak. Humanities and Social Sciences Communications, 7, 07 2020.
[2] B. Bley. Feldpostkarten im 1. Weltkrieg (Feldpost Postcards of World War I). Private Collection.
[3] M. Ehrmann, M. Romanello, A. Flückiger, and S. Clematide. Extended Overview of CLEF HIPE 2020: Named Entity Processing on Historical Newspapers. In CLEF, volume 2696, page 38, 2020.
[4] S. Liu, X. Zhang, S. Zhang, H. Wang, and W. Zhang. Neural machine reading comprehension: Methods and trends. Applied Sciences, 9(18), 2019.
[5] M. Mathew, L. Gomez, D. Karatzas, and C. V. Jawahar. Asking questions on handwritten document collections. IJDAR, 24(3):235-249, 2021.
[6] M. Mathew, D. Karatzas, and C. V. Jawahar. DocVQA: A dataset for VQA on document images. In IEEE Winter Conference on Applications of Computer Vision, pages 2199{2208. IEEE, 2021.
[7] E. Schubert, A. Spitz, M. Weiler, J. Geiß, and M. Gertz. Semantic word clouds with background corpus normalization and t-distributed stochastic neighbor embedding. CoRR, abs/1708.03569, 2017.
[8] R. Tito, D. Karatzas, and E. Valveny. Document collection visual question answering. In ICDAR, pages 778-792, 2021.
[9] R. Tito, M. Mathew, C. V. Jawahar, E. Valveny, and D. Karatzas. ICDAR 2021 competition on document visual question answering. In ICDAR, pages 635-649, 2021.